The AI Data Center Economy Runs on Tokens per Second per Watt
In early 2026, Microsoft disclosed an $80 billion unfulfilled Azure order backlog due to insufficient electricity to power the deployments. CEO Satya Nadella confirmed on the record that their GPUs are sitting idle in inventory, waiting for installations that can’t proceed until the grid can deliver the load.
Microsoft isn’t an isolated example. In the U.S. market, only 5 GW of the 12 GW of 2026 capacity announced by hyperscalers is actually under construction. Meanwhile, NVIDIA shipped roughly 10 GW of GPUs in 2025, and their own inventory has more than doubled year-over-year and quadrupled since 2024. All signs point to hyperscalers buying ahead of available power and locking in chip allocations for racks they can’t plug in yet.
The implication of these trends is that AI data center economics increasingly depend on the number of tokens produced per joule of electricity consumed. In his recent interview with Dwarksh, Jensen Huang describes how, once electricity is the scarce input, tokens per second per watt (Tokens/s/W), not FLOPs, becomes the most important data center metric.
Where tokens per joule matters most, every other infrastructure decision is downstream of that. At ElastixAI, we are helping develop the inference architectures that win in a Tokens/s/W economy.
The Token as the Unit of Revenue
In a training-dominated world, the relevant metric was FLOPS per dollar. Capital was scarce, compute was the bottleneck, and a successful data center needed to maximize compute per dollar of CapEx.
In an inference-dominated world, the metrics are different. When electricity – not compute – is the scarce input, the revenue line is a function of tokens served, priced per million, monetized through APIs.
In general, a data center operator’s revenue is the product of
Tokens generated per watt-second
Watt-seconds available
Dollars per token.
While the grid fixes the available watt-seconds, operators can still have significant influence over the other two.
This is one reason why NVIDIA’s Groq integration matters more than the headlines suggest. Groq’s LPX processors generate latency-sensitive tokens at higher-than-typical prices because users will pay a premium for fast response on agentic and reasoning workloads. By integrating Groq into the AI factory architecture, NVIDIA is implicitly conceding that no single architecture is optimal for every token.
When high-throughput batch workloads run on Blackwell, and latency-critical reasoning tokens run on Groq silicon, NVIDIA matches each chip to its optimal price tier, thereby increasing the data center’s revenue per watt. Segmentation is how hyperscalers optimize their physical assets for multiple revenue streams.
Inside the TCO of a Gigawatt
A one-gigawatt AI data center carries roughly $38 billion in upfront CapEx and approximately $900 million in annual OpEx, which, after CapEx is amortized across asset lifespans, amounts to roughly $8.5 billion in total cost per year. To understand why Tokens/s/Whas become the deciding metric, one must unpack the TCO of a real AI data center.
CapEx is More Than GPUs
Servers, and their underlying compute, account for roughly 60% of CapEx, about $23 billion of the $38 billion total. While compute accounts for the majority of cost, operators still tend to underweight the other 40% in their early planning. Other CapEx contributors include
Server internals: CPUs, RAM, local NVMe storage, motherboards, and PSUs.
Networking fabric: ConnectX-class NICs, InfiniBand or RoCE leaf-spine networking, optical transceivers, cabling.
Racks and cooling: The racks themselves. For example, in NVL72-class systems, each cabinet draws 120-132 kW and requires $5-$10 million per megawatt in direct liquid cooling retrofit.
Power distribution: Switchgear, UPS, transformers, busways.
The building shell: The physical facility that houses and protects everything above.
The land: If not utilized, multiple billion-dollar campuses can sit idle, influencing every dollar of chip CapEx.
OpEx is More Than Electricity
Power is the largest single OpEx line, but it is only one of several.
An operator who leases wholesale colocation often pays a single negotiated rate per kW per month. That rate is currently around $195 for primary North American markets, rising to roughly $215 in Northern Virginia. For a 100 MW facility, that works out to an annual lease of $234-$258 million. For a full gigawatt facility, that line scales to $2.3-$2.6 billion per year. Other factors include
Cooling water and treatment
Network transit and peering
On-site engineering and operations staff
Software licensing
Property taxes and insurance
Each of these extraneous factors scales with capacity but does not improve with utilization. Operators pay these costs regardless of whether their racks are producing tokens or sitting idle.
Why Tokens per Second per Watt Matters Most
Operators can calculate annual revenue as
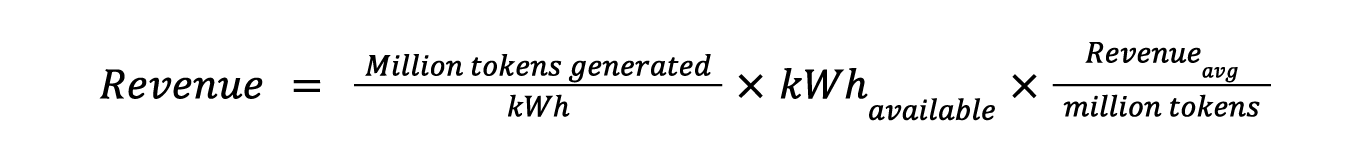
Of the three terms, their influences are shown in Table 1
| Revenue term | Influencing control |
|---|---|
|
Million tokens generated per kilowatt-hour (tokens per watt-second) |
Fully under operator control |
| Kilowatt-hours available | Determined by the grid |
| Average revenue per million tokens | Workload mix and NVIDIA-style market segmentation |
Table 1: Revenue variables and their influencing factors
Most operators don’t realize that the leverage is enormous. Consider a one-gigawatt facility operating at 95% utilization, generating tokens at 10 million tokens per kilowatt-hour (this is representative of a well-optimized Blackwell deployment running batched inference). Annual token output sits at roughly 83 trillion. At a blended ASP of $0.30 per million tokens across a mix of commodity and premium workloads, that gigawatt generates about $25 billion of gross token revenue per year. This is more than enough to clear the $8.5 billion annualized TCO with substantial margin.
Now apply a 5x improvement in tokens per kilowatt-hour. As shown in Figures 1 and 2, annual output rises to roughly 415 trillion tokens. Holding ASP constant, revenue rises to roughly $125 billion. The TCO line moves by single-digit percentage points, and the top line moves by 5x. The math is asymmetric, and it explains why every hyperscaler organizes their architecture roadmap around perf-per-watt rather than perf-per-dollar.
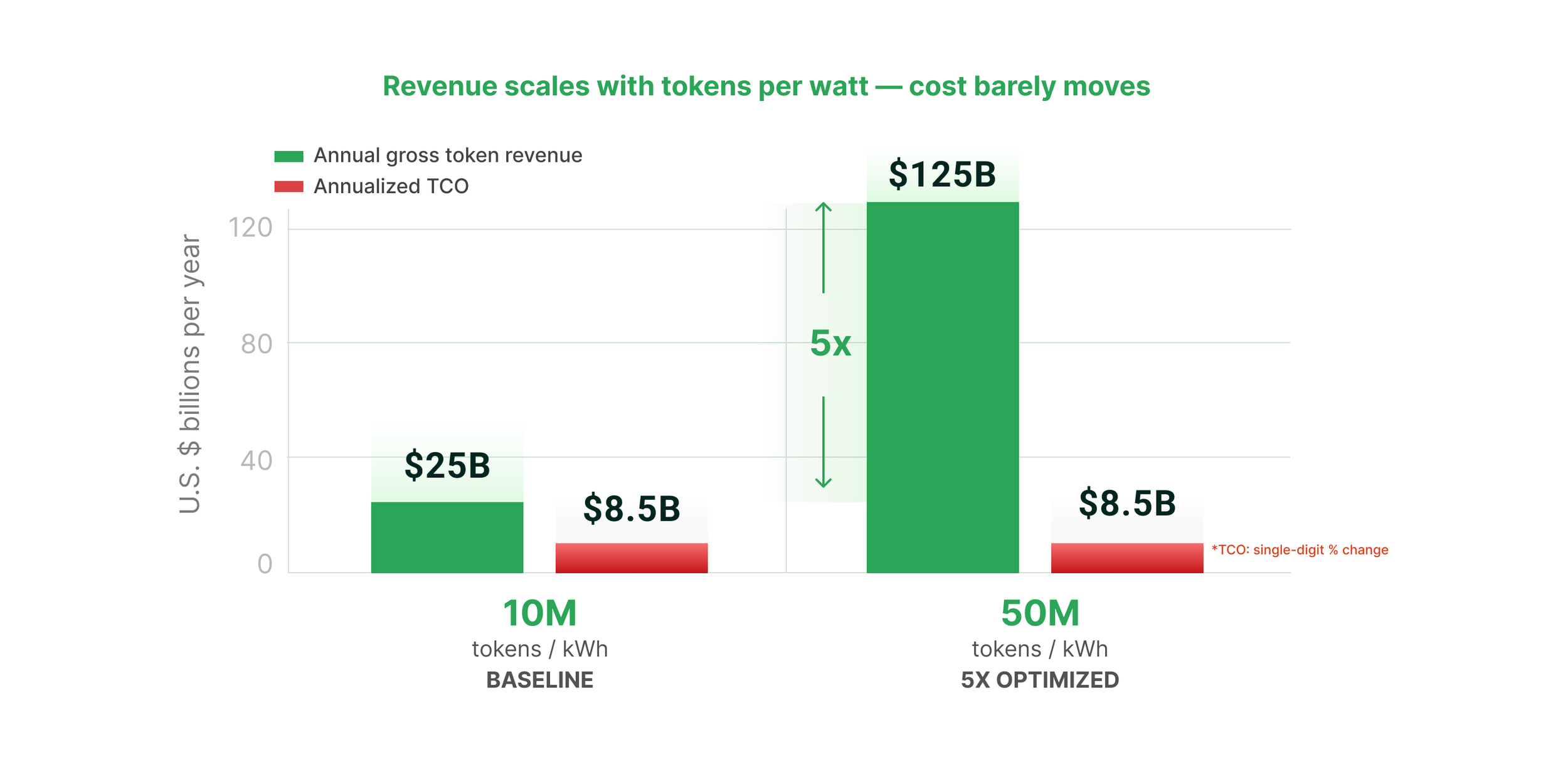
Figure 1: 1 GW facility at 95% utilization. Blended ASP held constant at $0.30 / million tokens.
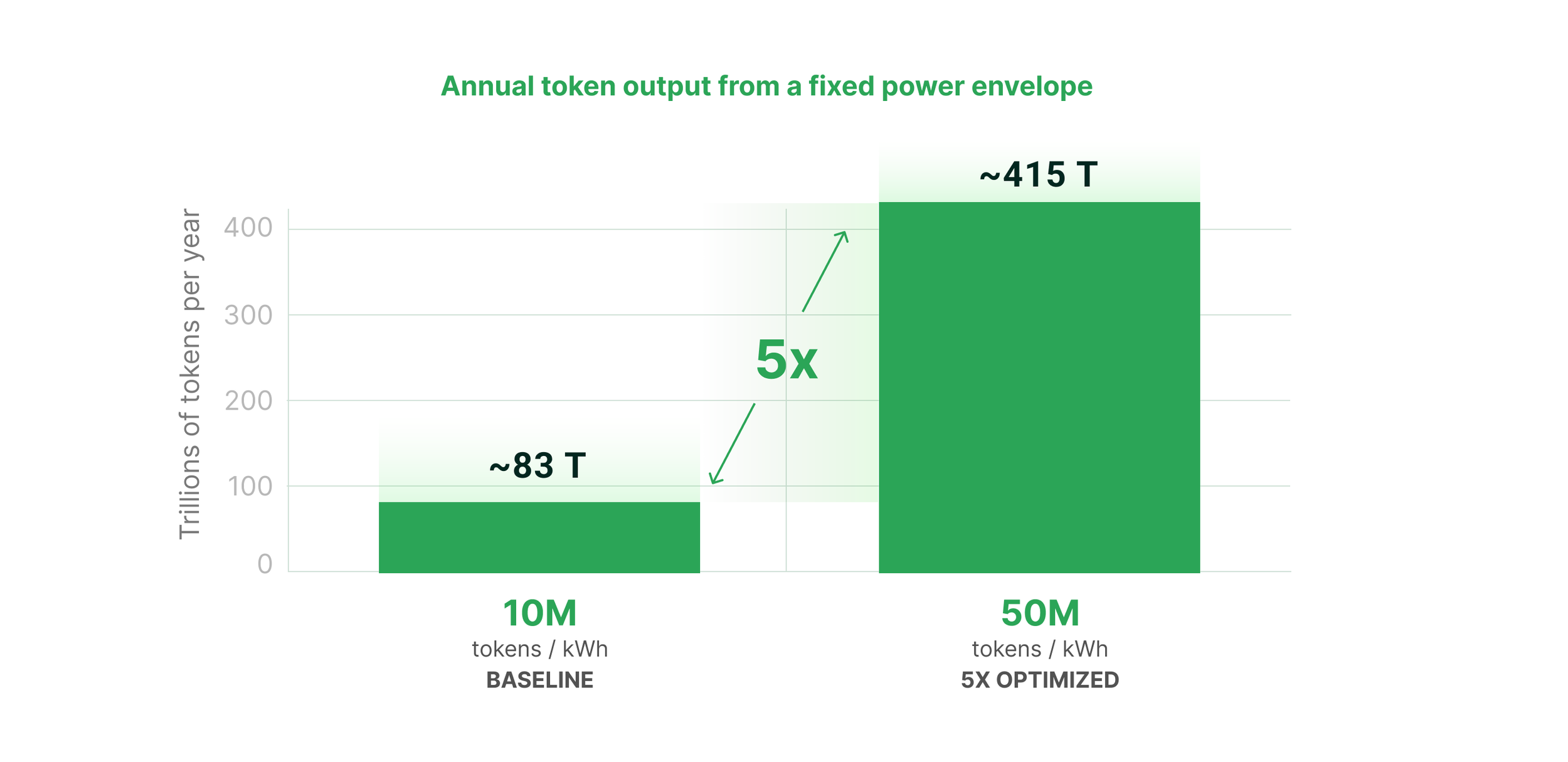
Figure 2: Same 1 GW, same grid allocation. Only tokens/s/W efficiency changes.
It also explains why dark silicon has become a major P&L concern. Independent performance analyses find that even when an LLM inference deployment shows near-100% GPU utilization, it typically sustains only 35-45% Model FLOPS Utilization (MFU). This means that more than half of an H100's theoretical compute goes unused, bottlenecked by memory bandwidth, KV-cache pressure, and the memory-bound decode phase. Operators pay for that idle capacity in both CapEx and power leakage.
Architectural Consequences
A Tokens/s/W perspective changes how operators should approach every layer of the inference stack. The operator’s job is to maximize revenue per watt the asset consumes. Three major implications stand out for operators planning the next deployment cycle.
Workload-Matched Silicon Wins
GPUs are general-purpose devices that can support training, scientific computing, and inference. But they are not the optimal solution for any single application, especially not inference.
Inference is structurally different from training. It has smaller per-step working sets, is decode-dominated, and is memory-bandwidth-bound rather than compute-bound. The core mismatch comes down to arithmetic intensity: the ratio of compute (FLOPs) to memory traffic (bytes) that the silicon can deliver versus what the workload actually needs.
Single-token decode operates at roughly 1-2 FLOPs per byte, far below the ridge point of a modern GPU, so most of the chip's arithmetic units sit idle waiting on memory. A processor with lower, decode-aligned arithmetic intensity would therefore be a more efficient solution than today's general-purpose GPU. Architectures purpose-built for decode (ASICs, low-latency LPX-class chips, or reconfigurable FPGA-based platforms) exploit exactly this. NVIDIA's own integration with Groq is evidence.
Memory Hierarchy Matters More Than FLOPS
Memory, not compute, is the single largest contributor to inference CapEx per token. In decode-bound LLM workloads, the joules spent moving weights and KV-cache data through the memory hierarchy outweigh the joules spent on arithmetic. That makes memory energy per token a primary determinant of tokens per second per watt.
The objective is to minimize the memory energy spent per token across the whole hierarchy. On the ML side, sparsity and extreme quantization reduce the number of bytes that the system must move. On the hardware side, a specialized dataflow implemented directly on an FPGA fabric can maximize on-chip reuse and keep data in the lowest-energy memory tiers as long as possible. Fixed-logic accelerators can't restructure their dataflow or adopt new quantization and sparsity schemes once taped out, but reconfigurable fabric can.
Procurement Over Architecture
The problem compounds during the chip's entire lifecycle. Bringing a new GPU architecture from design to mass production already takes roughly 2-3 years, but the clock doesn't stop at tape-out. Today's hyperscalers are sitting on multi-billion-dollar inventories of GPUs they can't deploy until power and cooling come online, which is increasingly a year or more away, and in the worst grid regions, it stretches to five years. Stack the two delays end to end, and a chip's journey from architecture definition to generating its first token can run close to five years. Given how fast AI workloads are moving, the silicon is often a generation or two behind the latest tape-out by the time it's finally plugged in. It’s rendered obsolete before operators can earn a dollar.
Operators can break this dependency with reconfigurable architectures. A fixed-logic GPU's design choices are frozen at tape-out, and every month spent waiting in inventory makes them increasingly obsolete. In contrast, designers can retarget reconfigurable platforms like FPGAs in software to match newer model architectures, quantization schemes, and attention patterns long after the silicon leaves the fab. For operators sitting on stockpiled hardware, this is the difference between bringing online near-state-of-the-art capacity and bringing online already-depreciated assets.
Rack-Level Power Density is a Constraint
Operators cannot deploy GB200 NVL72 racks at 120–200 kW per cabinet into the bulk of existing colocation footprints, which normally provision 17-19 kW per rack. Operators inheriting older capacity either must leave the rack at low density and surrender tokens per watt, or rebuild the power and cooling envelope at $5-$10 million per megawatt. The denser the workload, the more existing CapEx becomes effectively stranded.
Closing
The AI data center economy is now a function of Tokens per second per watt (Tokens/s/W), and dollars per token. NVIDIA, by integrating Groq into its inference stack, is positioning to compete on both at once. Hyperscalers buying inference capacity at scale will increasingly do the same, building portfolios of architectures matched to the latency and ASP profile of the workloads they serve.
At Elastix AI, we are building toward that future from the architectural side. Our software-ML-hardware co-design approach uses reconfigurable FPGAs to eliminate the dark silicon, memory inefficiency, and rigidity that limit Tokens/s/W on general-purpose accelerators, and to keep deployed capacity relevant as model architectures change and as new power capacity finally comes online. Our platform delivers a 5-50x TCO-per-token advantage on standard LLM inference workloads, at roughly 80% lower power consumption than comparable GPU-based deployments.
The infrastructure decisions made over the next 24 months will determine who has the highest-margin gigawatt in the industry for the next decade. For operators trying to extract more tokens from a fixed power envelope, Elastix AI’s advantages can make all the difference.