Five Reasons Why FPGAs Hit the Sweet Spot for LLM Inference
For years, the industry has been taking a brute force approach to AI hardware. As AI models have changed in nature and complexity, most have responded by simply scaling the same rigid architectures to larger footprints. We’ve thrown more High-Bandwidth Memory (HBM) and larger silicon dies at the challenge, yet the cost per token remains a barrier to truly ubiquitous AI.
The fundamental mismatch is systemic. Large Language Models (LLMs) are advancing at a weekly cadence of algorithmic breakthroughs. Meanwhile, the GPUs and ASICs designed to run them are locked into three-to-five-year hardware development cycles. This lag creates the well-known "Hardware Lottery" where brilliant optimizations are backburnered because today's custom chips – which were architected 3+ years ago – aren't wired to run them efficiently.
At ElastixAI, we’ve realized that the solution isn't a bigger chip. It’s a more adaptable one. By leveraging the reconfigurability of FPGAs, we can innovate at the ML optimization layer, co-design our software stack with our novel ML optimizations, and uniquely co-design all of these with the compute at near real-time. We are hitting a sweet spot that balances the efficiency of custom silicon with the agility of software.
Below are five reasons why FPGAs are now the right solution for LLM inference.
Reason #1: GPUs and the Trap of General Purpose
Modern GPUs are powerful in their own right, but they suffer from being overly general-purpose when applied to LLM inference. Engineers originally designed them to handle a massive breadth of workloads, including double-precision scientific simulations, video rendering, and, most recently, LLM training.
During LLM inference, however, the GPU’s inherent versatility becomes a liability. Inference is fundamentally different from training in that it’s a sequential, memory-bound process rather than a massive parallel-compute task. This leads to the dark silicon problem:
Wasted Logic: Large sections of a GPU’s die—logic meant for training-specific gradients or diverse operations—sit idle during inference.
Low Utilization: In typical data center deployments, state-of-the-art accelerators like the H100 often achieve less than 10% compute utilization for LLM workloads.
Power Waste: Operators effectively pay the power and CapEx tax on 100% of the silicon while receiving only 10% of the value.
FPGAs change the narrative by enabling software-defined specialization. Instead of forcing an LLM to run on a fixed architecture, ElastixAI uses the FPGA to generate a processor design that is a perfect 1-to-1 mirror of the model's specific requirements. We eliminate dark silicon waste by instantiating only the logic the model actually uses. FPGAs also offer the right balance of compute, memory bandwidth (arithmetic intensity), and chip-to-chip interconnect for LLM inference.
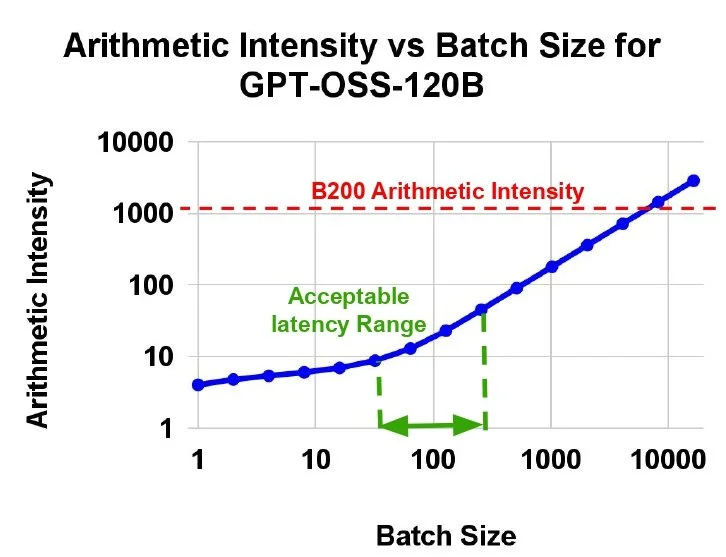
Typical batch sizes for MoE models inference during the decode phase require arithmetic intensities of <100, causing extremely low compute utilization on B200 for LLM inference.
Reason #2: The GPU Memory-Bandwidth and Cost Wall
The industry is currently facing a memory wall that is making LLM inference unsustainable. To understand why FPGAs are the solution, we have to look at the specific mechanics of token generation.
LLM inference is a memory-bound problem. During the decode phase, the processor must load the entire model’s weights from memory just to generate a single token. If your hardware cannot feed data to the compute cores fast enough, those cores sit idle, regardless of how many petaflops the marketing datasheet claims.
This has led to a scalability challenge as context windows expand and models grow in complexity. To compensate, AI accelerator manufacturers rely on Advanced HBM and SRAM, both of which are 10x and 10,000x more expensive per GB than standard DRAM or a slightly
older generation HBM, respectively. The result is a massive cost mismatch where memory, not compute, dictates the price of AI.
Fortunately, modern high-end FPGAs offer a way out of this economic trap. They provide effective memory bandwidth comparable to a B200 GPU but at approximately 1/3 the CapEx. By leveraging more CapEx-efficient memory designs and high-speed FPGAs, the ElastixAI architecture achieves elite bandwidth at a fraction of the price per GB/s. And, because our solution uses standard memory resources more effectively than general-purpose GPUs, we can scale memory capacity for massive KV caches while maintaining a 5-50x TCO-per-token advantage in high-volume production
Reason #3: Native Support for Novel Optimizations
The industry has only just begun to explore the potential of ML optimization, yet many of the most promising techniques remain unsupported by conventional hardware. ASICs and GPUs effectively freeze hardware design by imposing rigid constraints that stifle ML advancements. It’s for these reasons that the industry’s leading researchers have repeatedly called for new hardware approaches to support emerging breakthroughs:
Apple researchers have noted that running compressed models with lower bit rates is not well supported by conventional GPUs.
Microsoft Research has issued a call to action to design new hardware and systems specifically optimized for 1-bit LLMs, given the new computation paradigm enabled by BitNet.
Google Research shows that in the absence of hardware flexibility, researchers are forced to treat hardware as a "sunk cost" to work around rather than something fluid that could be shaped to fit the model.
The impact of bringing just one optimization natively into hardware is best illustrated by the leap from Nvidia’s Hopper (H200) to Blackwell (B200) architecture. The primary driver of Blackwell's improved cost efficiency (TCO/token) is not just silicon scaling, but the native hardware support for 4-bit quantization.

Cost per million output tokens vs. interactivity. Source: InferenceX as of February 24, 2026.
Data from InferenceX by SemiAnalysis as of February 24, 2026, has shown that for a model like DeepSeek-R1 at an interactivity of 41.6 tokens/s/user, the transition to native 4-bit support fundamentally changes the economic equation.
| Model Configuration | Hardware | TCO per 1M Output Tokens |
|---|---|---|
| 8-bit Model | H200 | ~$3.75 |
| 8-bit Model | B200 | ~$1.50 (~57% reduction) |
| 4-bit Model (Native) | B200 | ~$0.167 (Additional ~89% reduction) |
This massive step-function in cost efficiency was achieved by adopting a single, years-old ML optimization natively into the hardware. With an FPGA-based approach, you do not have to wait for the next generation of silicon to realize these gains. Instead, you can adopt these and even more advanced optimizations within days via a simple software update
Reason #4: FPGAs Are No Longer Just for Prototyping
Many in the industry have the false conception that FPGAs are only a viable solution for prototyping. This skepticism is outdated, rooted in a time when FPGAs lacked raw compute and required months of VHDL coding.
But, just as the AI industry has changed dramatically in the last few years, so too has FPGA technology. Modern server-grade FPGAs are no longer just logic gates. They contain:
Hard-Coded Compute Cores: Tensor-core-like blocks that handle dot-product operations at 5nm/7nm efficiency.
High Speed Memory: Leveraging HBM2E and GDDR6, these FPGAs deliver extremely high memory bandwidth.
High-Speed Interconnects: Native support for PCIe-5 and 800GbE.
Elasticity: The ability to update the hardware architecture via software in minutes, in some cases even dynamically during program execution.
With these advanced features, FPGAs provide the hardware resources to efficiently execute high-performance AI inference at scale.
Reason #5: ElastixAI Solves Development Complexity
Designers often fear that the FPGA toolchain is too complex. Historically, moving a model to an FPGA meant hiring a team of hardware engineers to spend months manually mapping logic. ElastixAI removes this barrier by making the hardware completely transparent to the ML researcher.
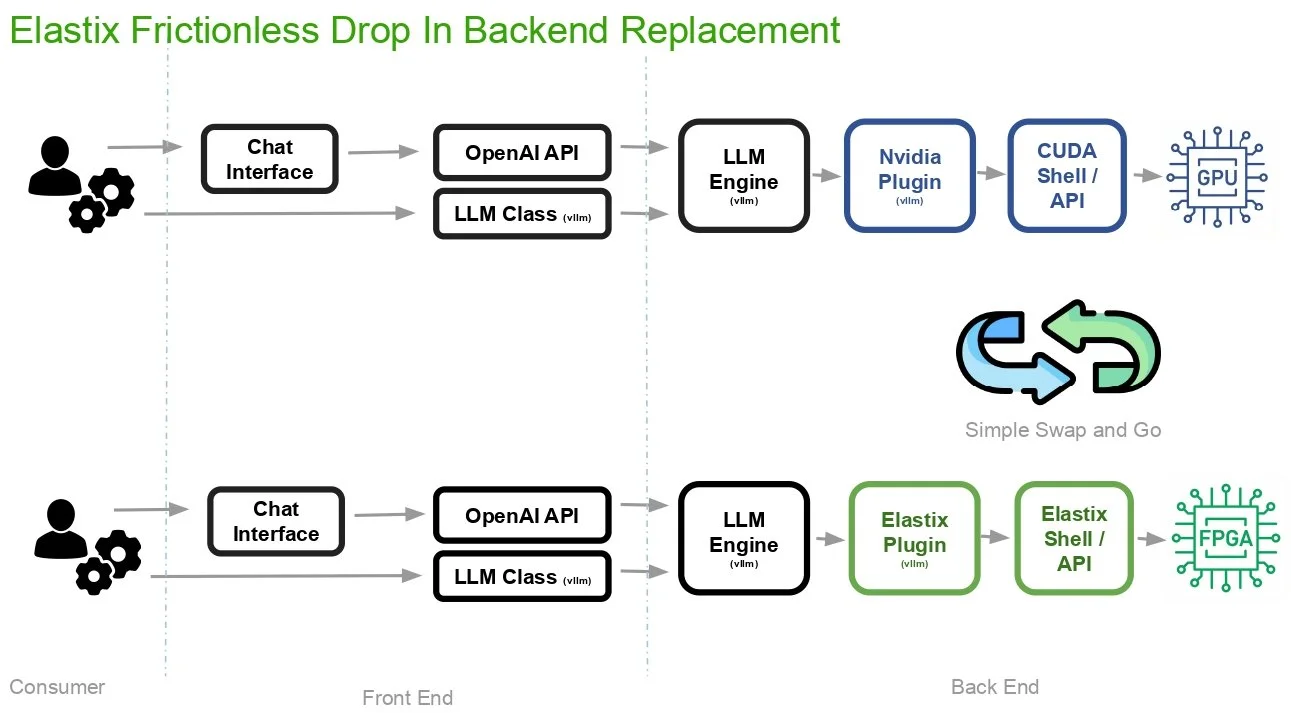
Elastix’s solution is a frictionless drop-in replacement for conventional GPU workflows.
At ElastixAI, our automated ML/HW/SW co-design stack acts as a compiler that translates standard models directly into optimized FPGA bitstreams. We provide a drop-in backend replacement for the NVIDIA plugin, allowing teams to maintain their existing workflow without writing a single line of low-level hardware code.
An Elastic Future
The industry is beginning to realize that inference silicon shouldn't be fixed until the algorithms themselves stabilize, which won't happen for years. If you bought H100s two years ago, you are now struggling to run the latest models efficiently because your hardware is literally stuck in the past. If those H100s were FPGAs, you wouldn't need a Blackwell upgrade. You would just need a software update.
At ElastixAI, we are building the infrastructure for the next generation of AI and finally letting developers innovate without the “Hardware Lottery” holding them back.