How ElastixAI Delivers the Lowest Cost per Token in LLM Inference
Large Language Models (LLMs) are advancing significantly faster than the hardware designed to run them. While the research community publishes breakthrough optimizations on a daily or weekly basis, the traditional silicon lifecycle takes three to five years. The result? AI progress is currently driven by hardware availability rather than the merit of the algorithms. Consequently, many promising algorithmic improvements are backburnered because the existing fixed-logic hardware can’t execute them efficiently.
Ultimately, there is a fundamental mismatch between the needs of GenAI inference and the offerings of modern accelerators. Because these chips are designed to handle a wide array of diverse workloads, they often leave significant efficiency on the table during the specific, high-throughput task of token generation.
The Architectural Bottlenecks of Fixed Logic
To deliver the lowest cost per token, ElastixAI addresses the glaring technical inefficiencies of current inference systems.
Dark Silicon and Underutilization
GPUs are built to be everything to everyone. This general-purpose nature necessitates vast tracts of silicon dedicated to logic that may never be used during a specific inference task. This results in "dark silicon": inactive parts of the chip that waste capital expenditure (CapEx) during purchase and operational expenditure (OpEx) through idle power leakage. In many typical data center use cases, less than 10% of a high-end GPU's compute capacity is actually utilized for LLM inference.
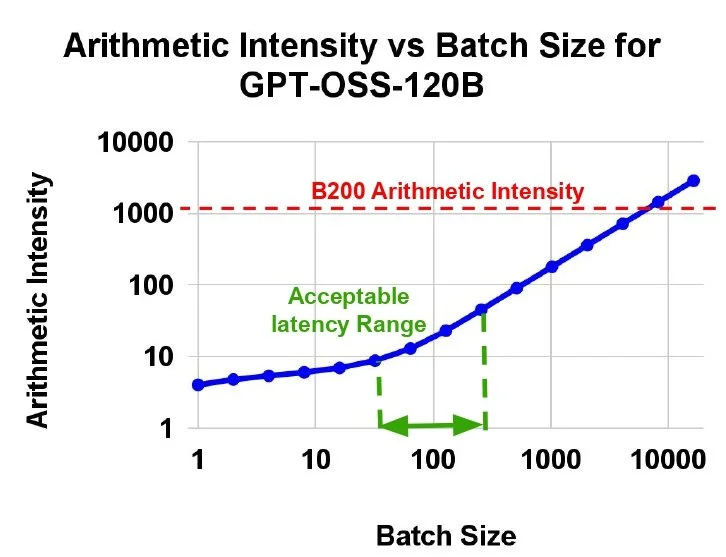
Typical batch sizes for MoE models inference require arithmetic intensities of <100, causing extremely low compute utilization on B200.
The Memory and Cost Mismatch
LLM inference is fundamentally a memory-bound problem, not a compute-bound one. Traditional architectures rely on High-Bandwidth Memory (HBM) and SRAM to keep up with the processing speed. However, these components are prohibitively expensive and difficult to scale. Advanced HBM costs 10x more per gigabyte than standard DRAM, while SRAM is a staggering 10,000x more expensive. This creates a memory wall, where increasing the context window for complex reasoning tasks leads to soaring infrastructure costs.
A Rigid Execution Pipeline
When a new optimization, such as 4-bit quantization, is introduced, fixed-logic hardware struggles to adapt. Because the physical data paths are set at the factory (often optimized for 8-bit or 16-bit), running a 4-bit model requires software workarounds. This leads to a massive gap between theoretical and realized gains. In this example, a 4-bit quantization might only yield a 10% performance improvement on fixed hardware, even though the theoretical gain should be closer to 100%.
The Solution: Elastix’s ML/HW/SW Co-Design Workflow
The path to true efficiency lies in breaking down the layers that currently comprise the inference stack. Rather than treating hardware as a fixed constraint, ElastixAI takes a holistic AI-optimization-first approach that treats hardware as a reconfigurable extension of the software. Our automated pipeline includes
Front-End Transparency: Developers interact with our system using existing, standard pathways such as the OpenAI API, vLLM LLM Class, and popular frameworks like PyTorch. That means no changes to existing application logic or code are required to access specialized hardware
Swap and Go Backend Logic: The infrastructure is a drop-in replacement for the existing GPU backends, replacing traditional NVIDIA Plug-in and CUDA Shell/API with our Elastix Plugin and Elastix Shell/API. The automated systems transparently routes neural computations to an FPGA instead of a GPU while maintaining the workflow for infrastructure teams.
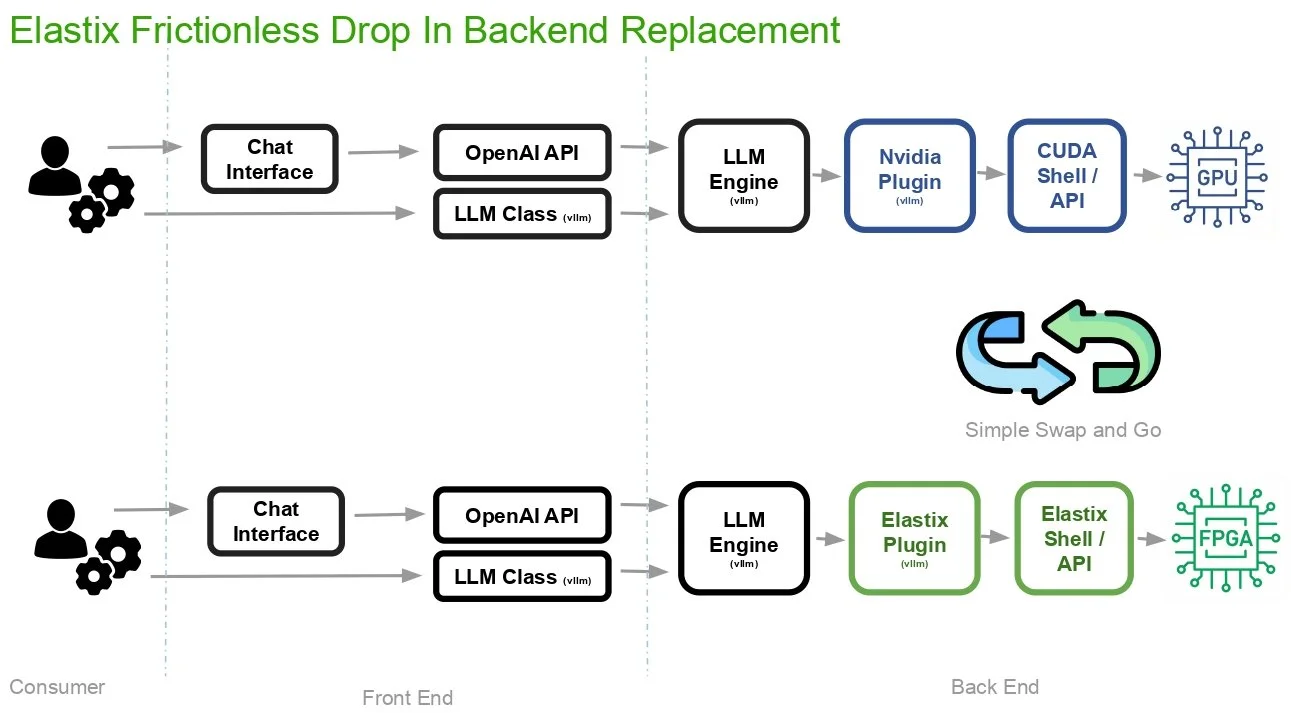
ElastixAI’s co-design workflow.
Economic and Operational Advantages
Immediately Implement Novel Optimizations
By using FPGAs, designers can rewire their hardware in seconds to meet the specific needs of a model. This eliminates the five-year wait for a new chip and enables designers to immediately implement optimizations from academia.
For instance, matrix multiplication is the basis of inference, but many of these matrices are "sparse," meaning they contain mostly zeros. Fixed GPUs are just beginning to support rudimentary sparsity patterns (like 2:4 sparsity), leaving the vast majority of potential gains untouched. A reconfigurable system can implement hardware acceleration for any sparse matrix pattern specified by the designer. By identifying and skipping zero-value calculations at the hardware level, the system can save both time and power.
Total Cost of Ownership (TCO)
By combining state-of-the-art FPGAs with proprietary ML optimizations, it is possible to achieve a 5-50x TCO per token advantage over standard GPU-based solutions. This advantage stems from lower CapEx (FPGAs are significantly cheaper than high-end B200 or H100 cards) and lower OpEx (due to higher compute utilization and 80% lower power consumption).
Solving the Data Center Power Mismatch
A significant hurdle for modern GPU deployment is power density. For example, a full rack of the latest GPUs can require 120-200 kW, while the vast majority of existing data center racks in the US are only equipped for 17-19 kW. A co-designed FPGA approach is much more modular. It can offer various operating points that fit into existing infrastructure without requiring expensive electrical retrofitting.
ElastixAI’s rack-level design prioritizes PCIe connectivity over power-hungry InfiniBand/NVLink, enabling designers to deploy high-density server nodes (up to 64 FPGAs) within standard power envelopes.
Supply Chain Resilience
Wait times for high-end GPUs can span years. FPGAs, by contrast, leverage more mature and diverse supply chains. This allows infrastructure teams to scale their token generation capacity in months rather than years, meeting the market's immediate demand.
Making Inference Affordable
Beyond just better models, the future of AI is about achieving the most efficient path to every token. If we don’t change our approach to computing, the costs associated with AI inference will soon become prohibitive. To truly unlock an affordable, efficient, and scalable future, our computing infrastructure needs to become as fluid and adaptable as the neural networks themselves. With our automated HW/ML/SW co-design platform, ElastixAI is making high-performance inference accessible for every enterprise.