Why AI Inference Could Be the Next Global Energy Crisis
The AI revolution has officially entered the stage of massive-scale deployment. But as organizations scale AI-powered applications to serve billions of daily queries, they are quickly finding that energy consumption is threatening their efforts.
While a compute-at-all-costs mentality drove the initial Large Language Model (LLM) arms race, the current bottleneck involves much more than silicon availability. Today, the primary constraints center on the capacity of a decades-old power grid and the thermal limits of modern data centers. To scale inference sustainably, the industry must look beyond general-purpose hardware and confront the architectural inefficiencies of the current AI ecosystem.
Why Inference is the New Energy Frontier
While model training imposes a high-intensity, one-time energy tax, inference imposes a continuous, compounding drain. As a result, this phase now dominates the AI energy footprint. As AI has scaled into mass deployment, research suggests that inference alone accounts for 60 to 80% of the total energy usage associated with AI models.
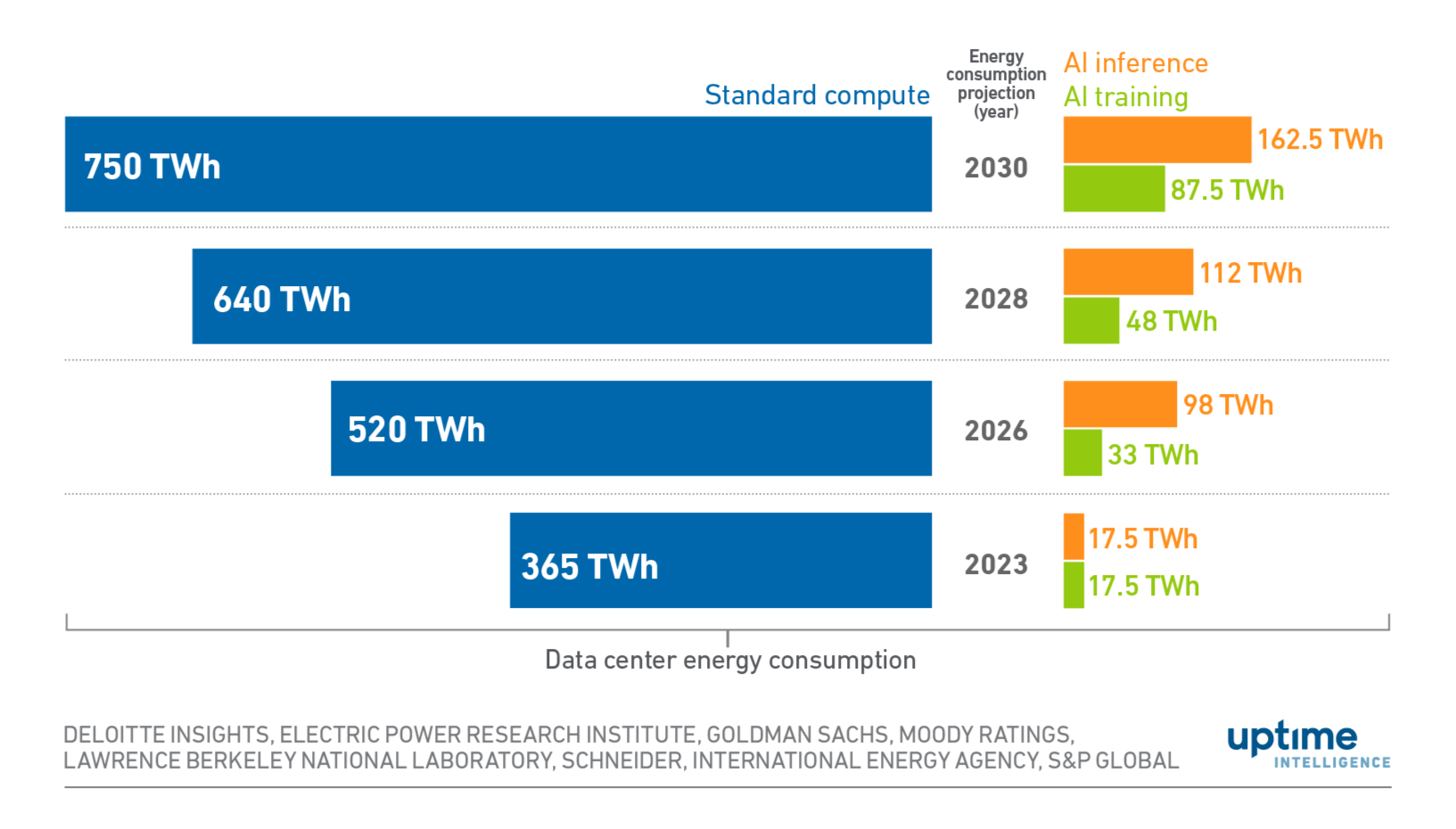
AI inference has quickly become a larger contributor to data center energy consumption than AI training. (Source: Uptime Institute)
Providing the appropriate energy for training was relatively easy. Since training is a predictable, one-time energy task, engineers can schedule it for off-peak hours or relocate workloads to grid regions with surplus green energy. In contrast, inference must happen instantly, wherever the user is located. That means that energy needs to be abundant and readily available at unpredictable schedules.
Ultimately, as AI becomes a ubiquitous utility, the energy required for inference creates a systemic burden. The industry is now reaching an inflection point where the demand for intelligence is at odds with the physical reality of power generation.
Wasted Compute and Data Movement
Standard approaches to AI inference rely on general-purpose GPUs originally optimized for training and heavy simulation. Unfortunately, these chips are proving inefficient for inference because they carry unused functionality that still consumes power.
Specifically, GPU architectures often contain logic that remains idle during specific inference tasks, a phenomenon known as dark silicon waste. This unused silicon still burns capital expenditure and leakage power without contributing to the workload.
Beyond the silicon itself, the way data moves inside a server creates massive energy overhead. In transformer-based models, moving data between memory and compute units often consumes more power than the actual mathematical operations. When a system must fetch billions of parameters for every token, the energy spent on data transport quickly dwarfs the energy spent on thinking. This inefficiency scales linearly with model size, making larger LLMs exponentially more expensive to operate as user bases grow.
Cooling is the Data Center’s Hidden Ceiling
Meanwhile, every watt of electricity consumed by a processor eventually exits the system as heat. High-throughput inference generates massive thermal burdens that have become the ultimate limiting factor in scaling AI infrastructure. In many modern data centers, the bottleneck is not the number of chips an operator can buy, but the amount of heat the facility can remove. Today, cooling systems account for nearly 40% of a data center’s total power draw.
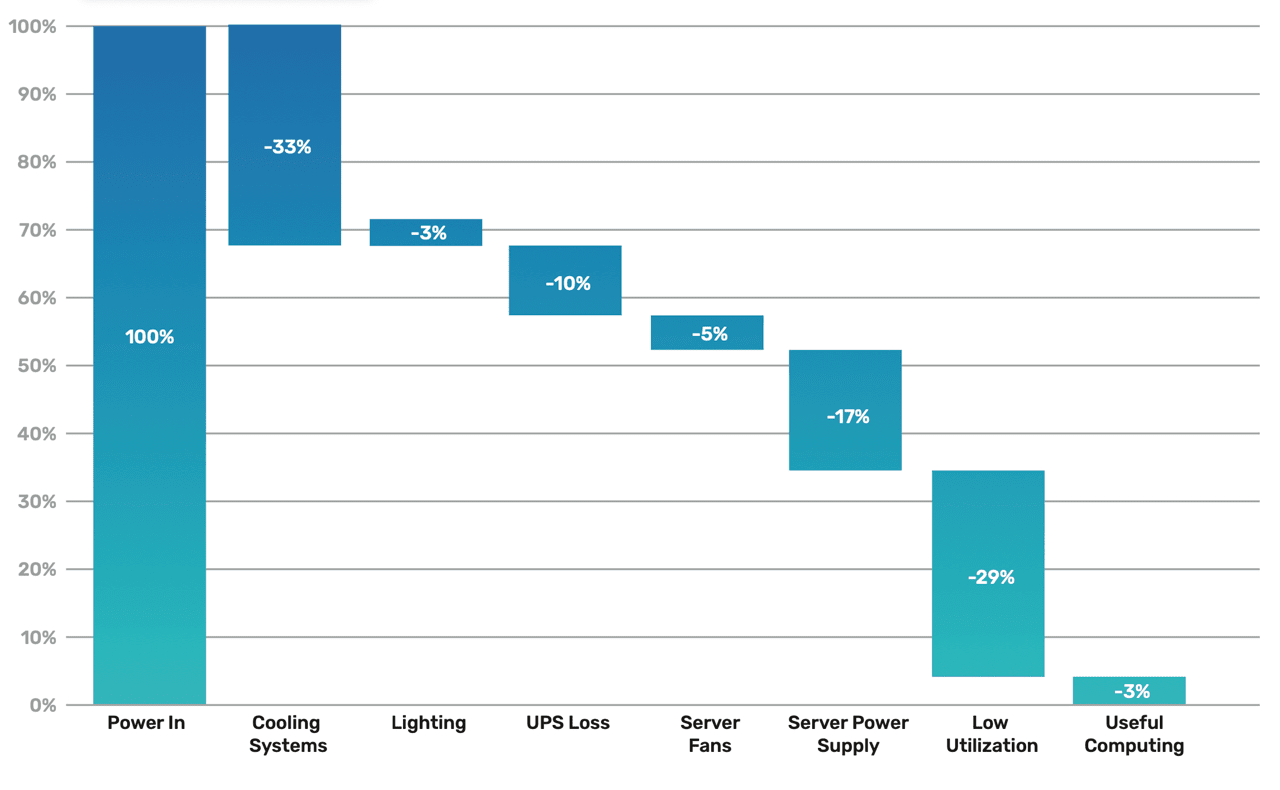
Cooling systems account for the majority of energy consumption in data centers. (Source: Semi Engineering)
When hardware runs inefficiently, it creates a thermal tax: operators must spend extra energy to cool the very hardware that is already wasting energy. Specialized hardware can break this cycle by reducing energy per token. With materially lower operating costs and thermal burden, specialized hardware unlocks higher inference capacity per megawatt (MW).
Global Implications on the Grid and the Consumer
The AI energy appetite carries consequences that extend far beyond the technology sector. Much of the US power grid infrastructure is decades old, and grid capacity expansion has not kept pace with the rising demand from AI data centers. This strain creates a ripple effect throughout the economy
Increased Consumer Costs: Utilities pass the costs of increased generation and infrastructure upgrades to consumers, meaning the average household electricity bill could rise as a direct consequence of AI adoption.
Grid Reliability: Regions with high concentrations of data centers face an increased risk of power shortages and reliability issues as the grid struggles to balance industrial and residential needs.
Environmental Impact: The carbon footprint of these models is immense. Training Llama 2 alone produced an estimated 539 tons of carbon dioxide equivalent, or nearly 72 times the annual output of an average US household.
Sustainability Deadlocks: Organizations struggle to reconcile their aggressive AI adoption goals with their public sustainability commitments.
As AI data centers compete for the same limited electricity supply, the cost burden is becoming a societal issue that affects energy security and environmental goals.
Full-Stack Co-Design and Reconfigurability
To solve the energy crisis, the industry needs to move away from rigid, general-purpose hardware toward full-stack co-design. This approach involves jointly optimizing the machine learning models, the serving software, and the hardware fabric to eliminate the waste inherent in training-optimized GPUs.
Full-stack co-design unifies software, ML optimizations, and hardware to deliver the most efficient AI solutions possible.
Architectural changes are already proving the viability of this path
Mixture of Experts (MoE): Architectures are adopting a sparsely-gated approach, where only a small fraction of the total parameters (the "experts") are activated for any given input. By using a gating mechanism to route data to the most relevant sub-networks, models can significantly scale their knowledge capacity while keeping per-token computational cost manageable.
Massive Model Pruning: Techniques like SparseGPT have demonstrated that massive language models can be accurately pruned in a single shot. This form of one-shot pruning removes redundant weights and creates sparse models that require far less data movement and fewer floating-point operations.
Low-Bit Quantization: Moving from 32-bit floating-point to 4-bit integers or even binary enables integer-only calculations. Research like Bitnet and TurboQuant both show that extreme quantization provides significant speedups through lower-precision arithmetic and better utilization of limited memory bandwidth.
Reconfigurable Fabric:Field-Programmable Gate Arrays (FPGAs) let the compute path adapt to the specific needs of an inference kernel. Contrasted to fixed-silicon chips, FPGAs can implement emerging optimizations natively in the execution pipeline without waiting years for a new hardware generation.
Moving Toward Sustainable Intelligence
The widespread adoption of AI has outpaced the energy efficiency of our current hardware infrastructure. We can no longer afford to scale AI by simply adding more power-hungry, general-purpose processors to already strained data centers.
Sustainable AI requires a new approach to building and deploying technology. By specializing the hardware fabric for inference and integrating it with optimized ML models, we can lower the total cost of ownership and reduce the burden on the global power grid. This energy-first approach will make the benefits of AI remain accessible without compromising environmental or economic stability.
Only by co-designing the full stack, from the algorithm to the silicon, can we build an AI future that the planet can actually afford to power.
Are you ready to optimize your inference stack for the energy-constrained reality of tomorrow?
To learn more about how full-stack co-design can reduce your energy footprint, email info@elastix.ai to explore the revolutionary technology we are building.